Use Cases: Text Annotation Services

Sentiment Analysis
By annotating customer reviews, social media posts, and survey responses, we create training data for AI models to facilitate sentiment analysis. It helps businesses gauge customer satisfaction and brand perception.
Intent Recognition
We label text data to help AI models identify the intent behind user queries, such as commands, questions, or requests. This improves the accuracy of virtual assistants and chatbots in understanding and responding to diverse user inputs.

Knowledge Base Linking
By linking text data to corresponding knowledge base entries, such as attaching a company name to its Wikipedia page, we help search engines and information retrieval systems to build knowledge graphs and boost their search relevance.

Topic Modeling
Through theme-based text annotation, large sets of unstructured data are categorized for topic modeling. This approach supports content recommendation, document clustering, and identifying emerging trends from vast volumes of text.
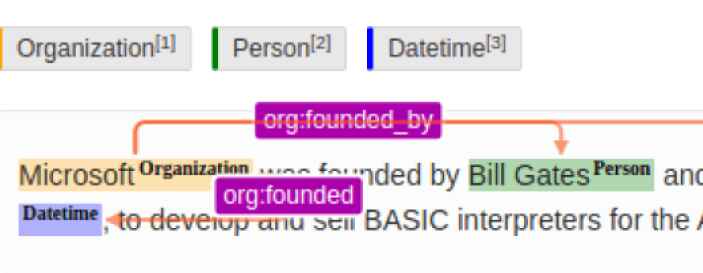
Automated Content Extraction
We label relationships between entities in text data, such as "employee of" or "located in," to support advanced content extraction, construction of knowledge graphs, and automated data retrieval by information systems.